
Linked lists, or single or double linked lists, are data structures that represent dynamic lists. The data structure is fundamental and consists of two classes, the list and the nodes.
The node class is responsible for storing the data, and references its predecessor and successor. You have to imagine such a list as if several persons were standing next to each other, each pointing to the person on his right side.
When working with a single chained list, you can only access the list at the so-called head, because head is the only access point. If you work with a single linked list, you can only go in one direction and that is next. In a doubly linked list, in addition to the entry point at Head, there is another entry point called Tail. With double chained lists you can not only go in the next direction but also in the prev direction. That means you can also go backwards through the list.
What can you do with this data structure? Actually everything you can do with buildin data types in Java, Python etc... also. Insert, search, delete, read the data at a certain position.
class Node
{
private:
int data;
Node *_next = nullptr;
public:
Node(int data);
~Node();
Node * Next();
void Next(Node* n);
int value();
void value(int data);
};
We consider the class definition from the header file "Node.h". There are 2 private attributes declared in the class. The attribute data, which stores the data set. The attribute _next of the data type of the class as a pointer, which points to its successor.
To see are, once the constructor, which takes the record directly as a transfer parameter. The destructor to dismantle the individual nodes and the instance itself.
The getter and setter, which are there once for the successor and the record itself. These access the private attributes data and _next reading and writing. The implementation, from the header defined class, looks like the following code example. Here we see the Node.cpp
#include "Node.h"
Node::Node(int data)
{
this->data = data;
}
Node::~Node()
{
this->_next = nullptr;
delete _next;
}
Node* Node::Next()
{
return this->_next;
}
void Node::Next(Node *n)
{
this->_next = n;
}
int Node::value()
{
return this->data;
}
void Node::value(int data)
{
this->data = data;
}
Here we see how the individual methods of the class Node are implemented. Nothing exciting. This class is the core of a single or double linked list. Each method has an overhead of . In the rest of the code we will go into more detail about the individual methods and salient points.
#include
#include "Node.h"
class List
{
private:
Node* head = nullptr;
Node* tail = nullptr;
int _size = 0;
public:
List();
List(int data);
~List();
void add(int data);
int size();
void remove(int pos);
void show();
int get(int pos);
void val(int pos, int data);
};
If we look at the definition of the header file "List.h", we see that 3 private attributes have been declared here. The two pointers head and tail point to the nodes at the beginning and end. The head pointer is the entry point from where we can access the list. If you delete head or set it to nullptr, all nodes referenced with head are lost in memory and you have a memory leak.
Why is the data lost, we do have Tail? Yes we have tail, but we can't go backwards through the list with tail, because we only have a _next pointer here.
Tail is the end of the list, alternatively you could have just set a nullptr at the last node instead of referencing tail. The third attribute _size* specifies the number of nodes, or the size of the list. This attribute is changed with every insert and delete operation.
Let's look at the two constructors. Once here we have the default constructor, and an overloaded constructor that has the parameter data. In detail, the implementation of the two constructors is as follows.
List::List() {}
List::List(int data)
{
Node *node = new Node(data);
node->Next(this->tail);
this->head = node;
this->_size++;
}
The default constructor has an empty body, because there is nothing to do here. It is also used in case we want to create an empty list. The overloaded constructor, however, creates a new node instance when called, and takes over the passed data set data. The new node is assigned tail as its successor, i.e. the end of the list. The pointer head is assigned to the new node to access the list later. Head is the anchor of the list. After that the attribute _size is increased by 1.
The destructor of the list, is somewhat more elaborate than the constructors. Here is an effort in the case, an empty list , and with a not empty list . Since every single entry of the list must be deleted to free memory.
List::~List()
{
if(this->head == nullptr || this->head->Next() == this->tail)
{
delete this->head;
delete this->tail;
}
else
{
Node* ptr = this->head;
while(ptr != this->tail)
{
Node* temp = ptr;
ptr = ptr->Next();
delete temp;
}
delete this->tail;
}
}
Here we see if the list is empty, only head and tail need to be deleted. Otherwise we create 2 pointers, one to wander and one to delete. Both together you have to imagine as a kind of sledge. With the two pointers, we go through the list. At the end, tail is deleted.

Let's consider the add method. With this method, we can add elements to the list. The overhead for a single chained list is , since elements can only be added at the end of the list.
For doubly chained lists, the overhead is , since we can add elements directly at the beginning or at the end.
This example is for single chained lists, for double chained lists examples will come later.
void List::add(int data)
{
Node *node = new Node(data);
if(this->head == nullptr)
{
this->head = node;
}
else
{
Node *ptr = this->head;
while(ptr->Next() != nullptr || ptr == tail)
{
ptr = ptr->Next();
}
ptr->Next(node);
}
node->Next(this->tail);
this->_size++;
}
The code of the add method creates a new node instance at the beginning. Practically, the data set is also transferred here. Here 2 cases are distinguished. Once the case, if the list is empty and once, if the list is not empty.
If the list is empty, head gets the newly instantiated node assigned. Otherwise, it must be migrated to the end of the list to add the new node at the end.
In both cases, the new node, tail is assigned as its successor. Then the attribute _size is increased by 1. Here we also have the overhead since most of the time we don't have an empty list.
The method size, gives the current size of the list. Here we have the attribute _size, which is changed with every operation. This saves us the effort of going through the list each time and counting the nodes. Here we only need to return the value of _size as in the example code.
int List::size()
{
return this->_size;
}
If we look at the method remove, we see that the structure is similar to the method add.
The code is written in a somewhat complicated way, and can therefore be simplified.
The method takes the parameter pos, which specifies the position of the node to be deleted. We also have 2 cases here, position 0 and position . If the list is empty, we don't need to do anything else here. Otherwise 4 pointers are created, one for the node to be deleted toDelete, one for its predecessor prev, one for its successor next and one to move through the list ptr.
void List::remove(int pos)
{
if(this->head == nullptr)
return;
Node *toDelete = nullptr;
Node *prev = nullptr;
Node *next = nullptr;
Node *ptr = this->head;
if(pos == 0)
{
toDelete = this->head;
this->head = toDelete->Next();
toDelete->Next(nullptr);
delete toDelete;
return;
}
if(pos >= this->_size || pos < 0)
return;
int i = 0;
while(ptr->Next() != nullptr || ptr != tail)
{
if(i == pos)
break;
prev = ptr;
toDelete = prev->Next();
next = prev->Next()->Next();
ptr = ptr->Next();
i++;
}
prev->Next(next);
delete toDelete;
this->_size--;
}
As already mentioned, there are 2 cases, position 0 and . If the case is that the position is , then we only need to set the pointer toDelete to head to delete this node later.
Simply deleting nodes is not possible. Here pointer bending is needed to avoid memory leaks and broken lists.
Head is set to the successor of toDelete, at toDelete the successor is set to nullptr. Once this is done, the node referenced by toDelete can be deleted. Here the overhead is .
Let's consider the second case, that of deleting at any position in the list. To delete a node, we must first check if the position is valid. That is, whether the position is within the list. Otherwise nothing is done and the method is exited.
We assume that the position is valid, and create a run variable , which is compared per step, with the passed position. If we have reached the desired position , then we can delete the node. Here first of all the pointers must be bent again so that the list still works afterwards.
The deletion takes place outside of the loop, but inside the loop the pointers (next, pref and toDelete) are selected. I think a small sketch says more at this point. One must imagine this as with the destructor as a sledge.
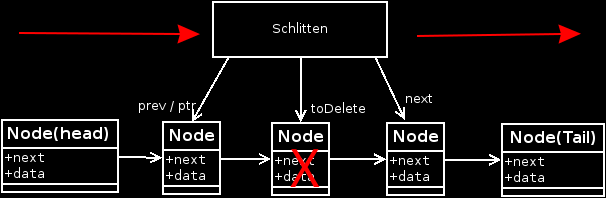
When we reach the position a break is made and the node prev points to its new successor next. The node toDelete is then simply deleted. The size _size is then decreased by 1.
void List::show()
{
if(this->head == nullptr)
{
std::cout << "[]" << std::endl;
return;
}
std::cout << "[";
Node * ptr = this->head;
while(ptr != nullptr || ptr != this->tail)
{
std::cout << ptr->value() << ", ";
ptr = ptr->Next();
}
std::cout << "]" << std::endl;
}
If we look at the method show, we will see quite quickly that this method simply outputs the whole list. Here also on 2 cases is differentiated (empty / not empty). Here then in the depending upon case, simply the empty list, or halt the value of the respective Nodes is indicated.
The method get works similar to the method remove. Here also a parameter pos is passed, which indicates the position of the node.
Here we check if the list is empty and if the position pos is valid. If this is not the case, we don't need to do anything and just return -1. Otherwise, similarly to the remove method, wander to the position pos, and then return the value of the node.
int List::get(int pos)
{
if(this->head == nullptr)
return -1;
if(pos >= this->_size || pos < 0)
return -1;
Node *ptr = this->head;
int i = 0;
while(ptr->Next() != nullptr || ptr != this->tail)
{
if(i == pos)
return ptr->value();
ptr = ptr->Next();
i++;
}
return -1;
}
Let's consider the method val. Here 2 parameters are passed. The position pos and the record data. With this method we can change the records of the individual nodes at any position in the list. The procedure is similar to the methods get and remove. Here only at the reached position, the record of the node is changed, with the call of the method value of the class Node.
void List::val(int pos, int data)
{
if(this->head == nullptr)
return;
if(pos >= this->_size || pos < 0)
return;
Node *ptr = this->head;
int i = 0;
while(ptr != this->tail)
{
if(i == pos)
{
ptr->value(data);
return;
}
ptr = ptr->Next();
i++;
}
}
All this is for single chained lists. For doubly linked lists, the situation is different. What does a doubly linked list look like? A small sketch shows it.

The class Node, gets another private attribute prev of the type Node. In addition, one getter and one setter each.
//Private attribute in the node.h
private:
Node* prev = nullptr;
public:
Node* Prev();
void Prev(Node* n);
//getter and setter in the Node.cpp
Node* Node::Prev()
{
return this->prev;
}
void Node::Prev(Node* n)
{
this->prev = n;
}
We can now convert the method add into two methods add_front and add_back, which both have the effort .
If we look at the method add_front, we see that 2 cases are considered here (empty / non-empty). If the list is empty, the new node is inserted between head and tail. Otherwise the node is inserted between head and the rest list (head->next).
void List::add_front(int val)
{
Node *newNode = new Node(val);
if(this->head->next() == this->tail)
{
this->head->next(newNode);
newNode->prev(this->head);
newNode->next(this->tail);
this->tail->prev(newNode);
return;
}
else
{
Node *temp = this->head->next();
newNode->next(temp);
temp->prev(newNode);
this->head->next(newNode);
}
this->_size++;
}
The same takes place with the add_back method, which is why we do not need to go into this again.
void List::add_back(int val)
{
Node *newNode = new Node(val);
if(this->head->next() == this->tail)
{
this->head->next(newNode);
newNode->prev(this->head);
newNode->next(this->tail);
this->tail->prev(newNode);
}
else
{
Node * prevNode = this->tail->prev();
prevNode->next(newNode);
newNode->prev(prevNode);
newNode->next(this->tail);
this->tail->prev(newNode);
}
this->_size++;
}
Both add methods can be converted to remove_front and remove_back. Since the node is deleted directly here, we have an overhead of in each case.
void List::remove_front()
{
if(this->head->next() == this->tail)
return;
Node *temp = this->head->next();
this->head->next(temp->next());
temp->next(nullptr);
this->head->next()->prev(this->head);
temp->prev(nullptr);
delete temp;
}
void List::remove_back()
{
if(this->tail->prev() == this->head)
return;
Node *temp = this->tail->prev();
this->tail->prev(temp->prev());
temp->prev(nullptr);
tail->prev()->next(this->tail);
temp->next(nullptr);
delete temp;
}
The methods pop_front and pop_back, where we get the value and the node is deleted afterwards. These are identical in structure. The only difference is that before the deletion, the record is read. Here we have an overhead of in each case.
int List::pop_front()
{
if(this->head->next() == this->tail)
return;
Node *temp = this->head->next();
int v = temp->value();
this->head->next(temp->next());
temp->next(nullptr);
this->head->next()->prev(this->head);
temp->prev(nullptr);
delete temp;
return v;
}
int List::pop_back()
{
if(this->tail->prev() == this->head)
return;
Node *temp = this->tail->prev();
int v = temp->value();
this->tail->prev(temp->prev());
temp->prev(nullptr);
tail->prev()->next(this->tail);
temp->next(nullptr);
delete temp;
return v;
}
If we look at the remove method, we see that it is a bit shorter than the simple chained list. Here we also check if the list is empty or not. Otherwise, the list is wandered to the desired position, and the pointers are bent so that the predecessor of the affected node points to the successor of the affected node, and vice versa. Here the effort is since we must wander through here in the Worstcase to the end of the list.
void List::remove(int pos)
{
if(this->head->next() == this->tail)
return;
Node * ptr = head->next();
int i = 0;
while(ptr->next() != nullptr || ptr != this->tail)
{
if(i == pos)
{
Node * prevNode = ptr->prev();
Node * nextNode = ptr->next();
nextNode->prev(prevNode);
prevNode->next(nextNode);
ptr->next(nullptr);
ptr->prev(nullptr);
delete ptr;
return;
}
ptr = ptr->next();
i++;
}
_size--;
}
The rest is similar to the simple chained list. The whole thing could be extended e.g. search, keys (key-value memory) etc....
I hope I could provide a small insight into chained lists 😄