
Hi, I thought I would do something about binary search trees.
What is a binary search tree?
A binary search tree, is a data structure, which organizes data, in the form of a tree. There are different types of search trees, such as AVL tree, red-black tree, 234 tree, B tree as well as the (B+) tree. Here in this post, I cover the simple search tree.
First of all, what does a binary search tree (BST) look like? When I had made the post where I had built with the composite pattern, a file system, that was to compare with binary search tree.
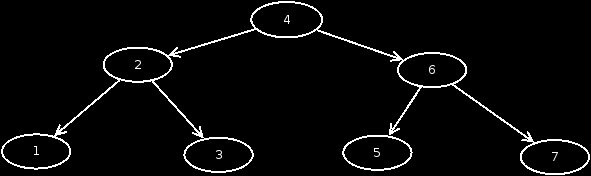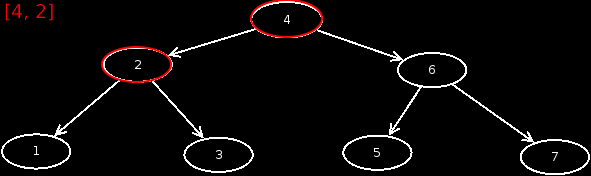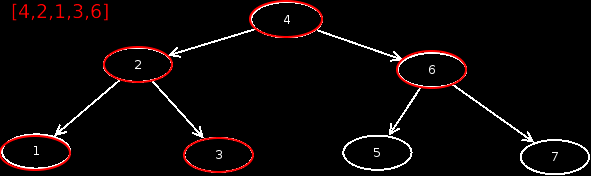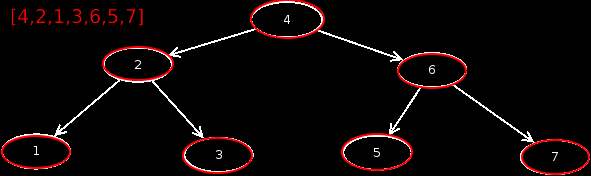
A small sketch shows how a binary search tree looks like.

In a binary search tree, for the basic operations (insert, delete and search, as well as read), we have an effort , which is quite good. But in the worst case, when the tree degenerates to a list, we have the effort .
In this data structure, there is a rule that must be applied to the tree all the time. This rule says that all values that are smaller than the value of the root, move to the left side of the tree. Everything that is larger, to the right side. The same can happen in reverse. By default, the former is the case. This is applied to any node-child relationship.
In a BST, each node has a maximum of 2 child nodes.
How does it work, and how to implement?
Let's make a BST. We have the values , and we should insert them into a BST. A small animation shows how this works exactly.

If we now search for a node through a BST, we must start from the root and move through the tree. Thereby we also consider the rule, that if the searched value is smaller, we move to the left, otherwise to the right. An animation shows this in more detail.
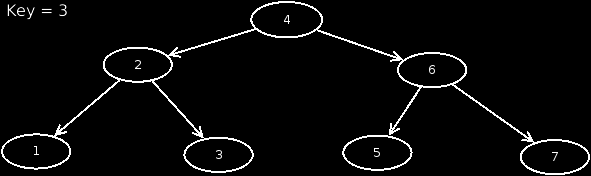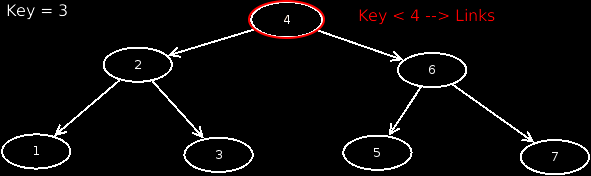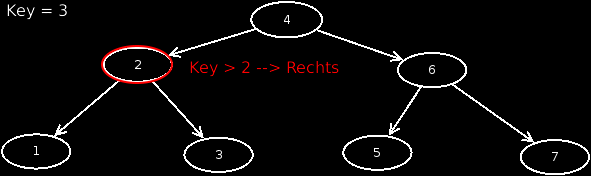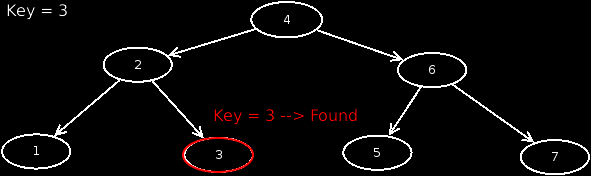
Suppose we search for a node that does not exist in our BST, what would happen? Exactly, nothing.
If we want to output the tree, we have to start at the root again. From the root, walk through the entire tree. Each node we find, we then output.
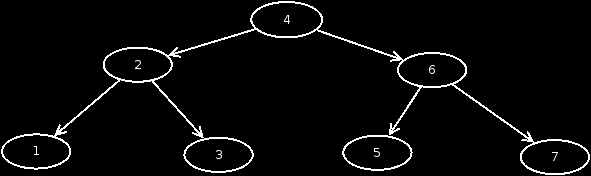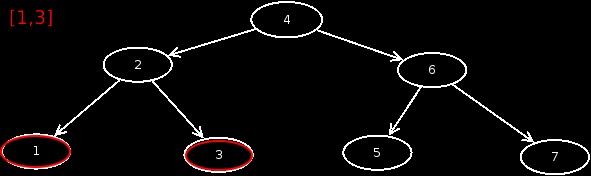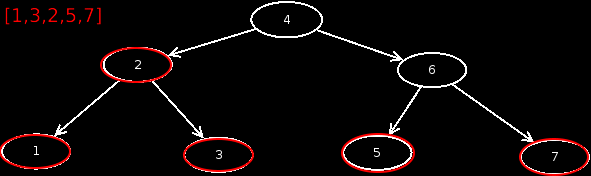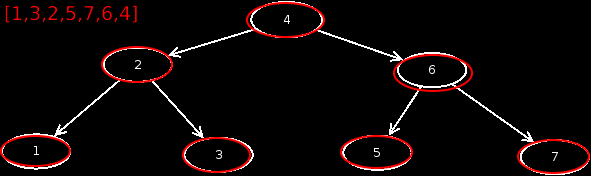
Preorder
This output is preorder. This means that we first output the current node, then visit the left child, and then visit the right child.
Preorder =
Inorder
With Inorder, the output is a little different. First, from the current node, we visit the left child, and output it. Then the current node, and then the right child. Inorder =
An animation shows how Inorder works.
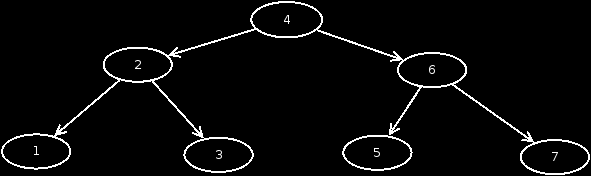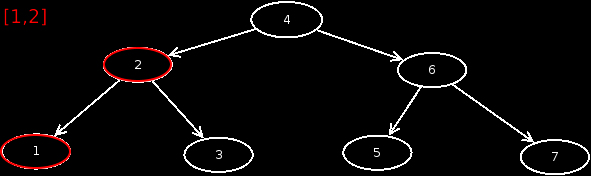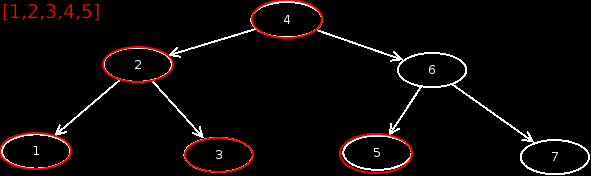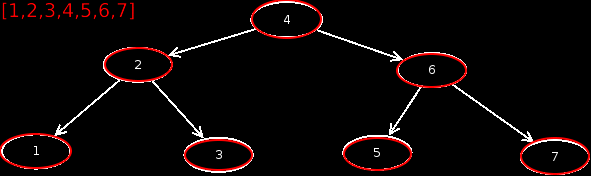
Yes, if the tree is built correctly, as in this case, we get a sorted output of the values. So you can also sort with BST's.
Postorder
With postorder, we go off the left child first, followed by the right child, before we output the current node. This looks in the animation, like this.
Postorder =
Deleting nodes from the tree
Now we just have to see how to delete nodes from the BST. Here there are 5 cases, which must be considered.
-
Case 1: The tree is empty. In this case, we don't have to do anything.
-
Case 2: The node has no children. In this case, we only need to delete the node.
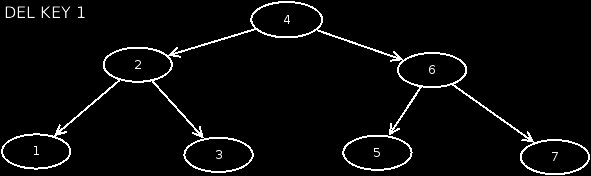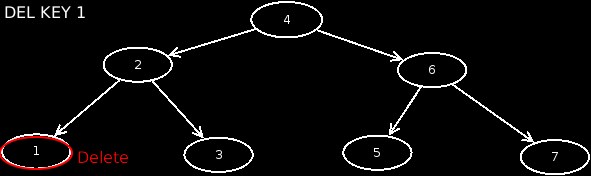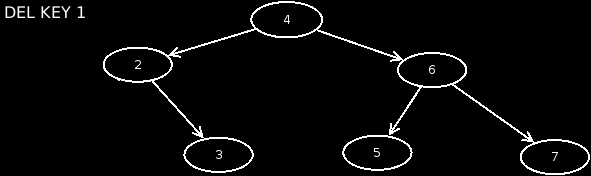
-
Case 3: The node has a child on the left side. In this case, we keep the child node. We assign it as the left child to the parent node of the node to be deleted. Then we delete the affected node.
-
Case 4: Same as case 3, but for the right child.
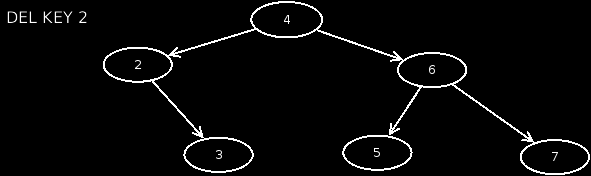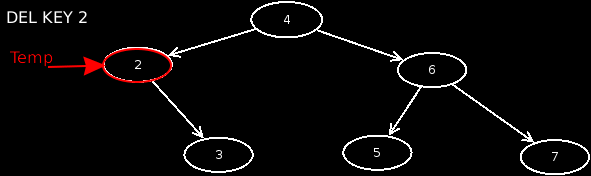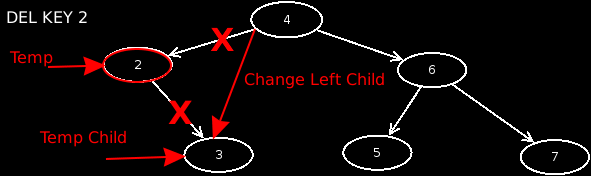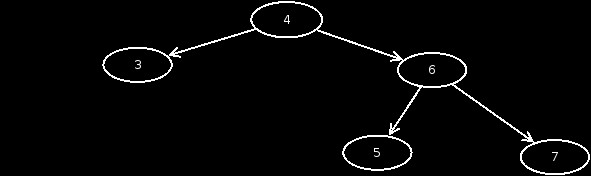
- Case 5: The node has 2 children. In this case, we look for the minimum from the right subtree, which has no children. We then exchange the value of this node with that of the affected node, and then delete the minimum node in the right subtree.
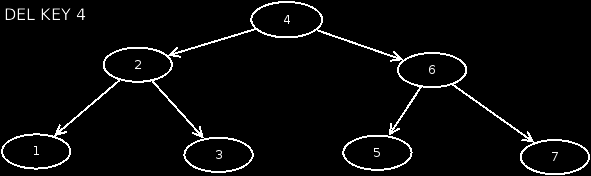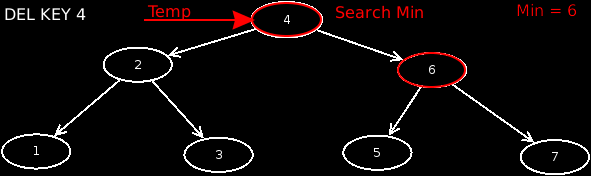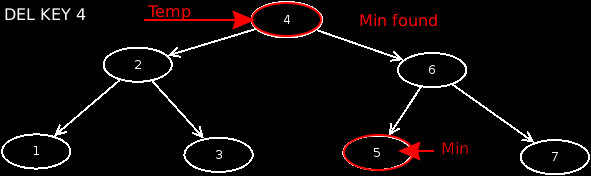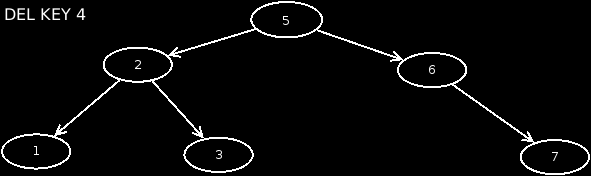
These are the basic operations on a tree. Let's implement this in Java. We need only 2 classes for this. One is the class Node, which refers to child nodes and stores the data set. On the other hand the class Tree, which should manage all nodes. Here, the basic operations will be implemented later.
Implementation of the tree
Let's move on to the Node class. The implementation is quite simple.
package com.strider.dev;
public class Node
{
private int key;
private Node left = null;
private Node right = null;
private Node parent = null;
public Node(int key)
{
this.key = key;
}
public int getKey()
{
return key;
}
public void setKey(int key)
{
this.key = key;
}
public Node getLeft()
{
return left;
}
public void setLeft(Node left)
{
this.left = left;
}
public Node getRight()
{
return right;
}
public void setRight(Node right)
{
this.right = right;
}
public Node getParent()
{
return parent;
}
public void setParent(Node parent)
{
this.parent = parent;
}
}
If we look at the code, from the Node class, we see 4 private attributes. Two, which refer to the left and right child. An attribute that points to the parent node of the node, and an attribute to store the data. For the attributes there are corresponding getters and setters. The constructor is kept simple here, as only the key, is passed as a parameter. The key is our data set. The references are here set to zero, so that we know later, where what is free.
If we want to implement the class Tree, we have to think about the structure. For this, I have defined a single attribute root, which later refers to our, root node. Furthermore we find here, also the default constructor.
package com.strider.dev;
import com.strider.dev.Node;
public class Tree
{
private Node root = null;
public Tree() { }
}
When we extend our Tree class with a method that allows us to insert data, we need to consider two cases. The first case would be that the tree is empty. The second case is that the tree is not empty.
public void add(int key)
{
if(this.root == null)
{
this.root = new Node(key);
this.root.setParent(null);
return;
}
add(this.root, key);
}
private void add(Node root, int key)
{
if(root == null)
return;
if(root.getKey() < key)
{
if(root.getLeft() == null)
{
Node n = new Node(key);
root.setLeft(n);
n.setParent(root);
return;
}
add(root.getLeft(), key);
}
else
{
if(root.getRight() == null)
{
Node n = new Node(key);
root.setRight(n);
n.setParent(root);
return;
}
add(root.getRight(), key);
}
}
If we look at the method add, we see that there are 2 different versions. Once a public method, with which we can insert the data. The private method is called by the public method when the second case occurs.
In the first case, we can simply create a new node and assign it the root attribute. This node is simply assigned a null as its parent node, since no parent node exists. This node is now our root node. In the second case, we need to go to the private method. Here we pass the record to insert and the root node. The first thing that is checked is the case that our passed node is a null. If this is the case, we do nothing, otherwise we get a NullPointerException, because we cannot query the node value and its children.
Otherwise, we check if our data set is smaller than the data set of the current node. If this is the case, we check if said node has no left child. If this is the case, we can create a node, assign it as a left child to said node. Otherwise, we go one node to the left, that is, to the left child. A recursive call is then made to do this. The same happens in the "else" part, only for the right subtree.
If we now extend our class to include Preorder, we see that we also have a two-part method here. That is, a public and a private method.
public void preorder()
{
if(this.root == null)
return;
preorder(this.root);
}
private void preorder(Node root)
{
System.out.println(root.getKey());
if(root.getLeft() != null)
{
preorder(root.getLeft());
}
if(root.getRight() != null)
{
preorder(root.getRight());
}
}
Here we see a similar structure as with the method add. Here in the public part, it is checked whether the tree is empty. If this is not the case, we traverse the tree to Preorder.
Here, the current node is output first. Then we check if there is a left child of the current node. If so, we make a recursive call and traverse to the left child. After that we move to the right child, if possible.
The whole thing is then done until the whole tree is output in Preoderstyle.
Inorder is similar to Preorder. Let's just have a look at the code.
void inorder()
{
if(this.root == null)
return;
inorder(this.root);
}
private void inorder(Node root)
{
if(root.getLeft() != null)
{
inorder(root.getLeft());
}
System.out.println(root.getKey());
if(root.getRight() != null)
{
inorder(root.getRight());
}
}
If we take a closer look at the code, we see that the structure is exactly the same. The only difference here is the position of the println. This is now between the two if queries. Postorder is, surprise, surprise not much different either. The println is at the end.
public void postorder()
{
if(this.root == null)
return;
postorder(this.root);
}
private void postorder(Node root)
{
if(root.getLeft() != null)
{
postorder(root.getLeft());
}
if(root.getRight() != null)
{
postorder(root.getRight());
}
System.out.println(root.getKey());
}
Now we can insert and output data. The node search is a modified inorder method, which only outputs the searched nodes. What now needs to be implemented is the deletion.
Min, Max & delete nodes
Here I have created two more methods, which can determine the smallest or the largest node.
public Node findMinNode(Node root)
{
if(root.getLeft() == null)
return root;
return findMinNode(root.getLeft());
}
public Node findMaxNode(Node root)
{
if(root.getRight() == null)
return root;
return findMinNode(root.getRight());
}
These two methods return the smallest or the largest node. For deleting, we only need the first method. The delete method is similar to our other methods. There is also a public and a private part.
public void delete(int key)
{
if(this.root == null)
return;
delete(this.root, key);
}
private void delete(Node root, int key)
{
if(root == null)
return;
if(root.getKey() < key)
{
delete(root.getLeft(), key);
}
else if(root.getKey() > key)
{
delete(root.getRight(), key);
}
else
{
if(root.getLeft() != null && root.getRight() == null)
{
Node p = root.getParent();
Node c = root.getLeft();
c.setParent(p);
p.setLeft(c);
root = null;
}
else if(root.getLeft() == null && root.getRight() != null)
{
Node p = root.getParent();
Node c = root.getRight();
c.setParent(p);
p.setRight(c);
root = null;
}
else if(root.getLeft() != null && root.getRight() != null)
{
Node temp = root;
Node min = findMinNode(root.getRight());
root.setKey(min.getKey());
delete(root.getRight(), min.getKey());
}
else
{
Node p = root.getParent();
if(p.getLeft() == root)
{
p.setLeft(null);
}
else
{
p.setRight(null);
}
root = null;
}
}
}
In the public part, we check if our tree is empty. If yes, we do nothing. Otherwise, we go to the private part. We also start here, always from the root.
In the private method, we first check if our record is smaller than the record of the current node. After that, whether it is larger.
Once we have found our node that we want to delete, we end up in the "else" part. Here the cases 2-5 are implemented. Once the case that the node has no children. Here we only have to delete the node. Then the case that we have either a left child or right child. Here we simply overwrite the node with the child and delete it. Since we have a garbage collector here in Java, we don't have to worry about explicit deletion.
The last case is when the node has 2 children. Here we look for our minimum on the right subtree of the node, because otherwise we will break the tree. Once we have found it, we assign the value of the minimum account to the current node. Now we simply delete the minimum node. Here to another recursive call is made.
I hope I could give some insights, to binary search trees 😄