
Hi, in the seventh and last part of my graph series, I want to talk about Dijkstra's algorithm. We have programmed Kruskal in Python in the sixth part. Now it's time to move on to Dijkstra.
What is Dijkstra?
Dijkstra is an algorithm, with which one can determine the shortest paths, between 2 different nodes. Dijkstra is also a greedy algorithm, which can be applied to directed and undirected graphs. Dijkstra is also used in network engineering, e.g. for routing or Google Maps. Ok, before we continue, let's get the graph in front of us again.
Dijkstra is a greedy algorithm as mentioned before. Dijkstra is similar to Prim. However, here we have the advantage of being able to calculate the shortest path from any node to another node. Dijkstra goes and looks at its starting node to see which nodes it can reach. He lists these in a table. The nodes that can be reached are entered as weights in the respective column. The ones that can't be reached are entered with an infinite weight. If this node was examined, Dijkstra looks out from the table, the smallest weight from the line (current node) and visits the adjacent node. Also here Dijkstra examines, which nodes can be reached here. New nodes, are also entered in the respective columns as weight. If there is a node with a weight that is smaller than an already existing weight, the summed weight is entered here. The whole Bumbs is repeated as long as, until all nodes were visited.
A small example using the graph, shows how Dijkstra works.
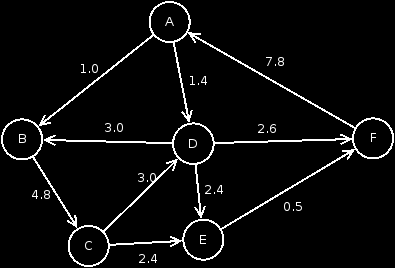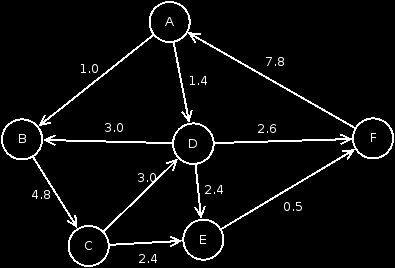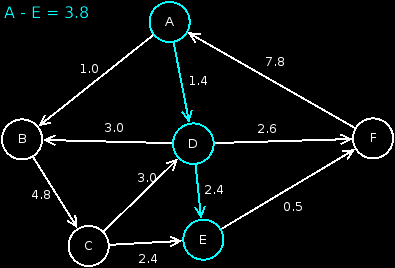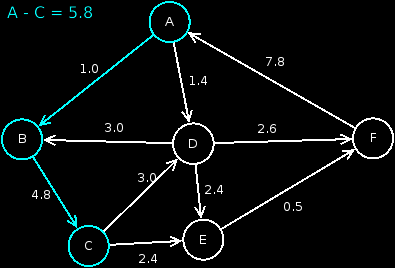
As seen in yellow marked the final distances / weights that go to the respective nodes from . Blue is always the smallest node not yet treated.
Extend our graph implementation
Ok, let's just extend the Graph class with Dijkstra. I have implemented Dijkstra via 5 method. One method header and the main method and three auxiliary methods. Ok let's get to the helper methods first. Let's start with the auxiliary method __connected.
def __connected(self, A, B):
node = self.getNode(A)
for edge in node.getEdges():
if edge.getB().getKey() == B:
return True
return False
This method checks whether the two nodes and are connected to each other. To do this, all edges of node are simply checked to see if node is included. If this is the case, both nodes are connected. Otherwise they are not.
Let's turn our attention to the method getWeightBetween. This method determines the weight of the edge, between node and .
def __getWeightBetween(self, A, B):
node = self.getNode(A)
for edge in node.getEdges():
if edge.getB().getKey() == B:
return edge.getWeight()
return 2 ** 32
The structure is exactly like the __connected method, only that the weight is returned. Otherwise 4.3 billion which is to be considered as infinite. Small tip this method can be used alternatively, whether nodes are connected or not. I did not make that for explanation reasons, times.
The method minDistance, determines the node with the shortest distance, which is not yet contained in shortest paths.
def __minDistance(self, paths, include_shortest_path):
min = 2 ** 32
i = None
for node in self.__nodes.values():
if include_shortest_path[node.getKey()] == False and paths[node.getKey()] <= min:
min = paths[node.getKey()]
i = node
return i
Here we see that we create a minimum min which is infinite for now. We also create a variable i, which should save us the node with the smallest distance between. The parameter paths is our table which contains the shortest paths. The parameter include_shortest_path is a checklist of all the nodes that are included in the shortest paths. If a node exists that is not yet listed and is the node with the shortest distance, it is cached until a better node is found. At the end we return our found node, otherwise a None.
If we take a look at the method header, we won't be able to say much.
def dijkstra(self, start, end):
paths = self.__dijkstra(start)
print(paths[end])
Here we see that a submethod dijkstra is called, which is passed our start node. After the call, we get the path list, which contains the shortest paths from the start to the other nodes. At the end, we simply output the distance from the start node to the end node.
Our main method dijkstra, is built a bit more complex.
def __dijkstra(self, start):
paths = {}
include_shortest_path = {}
for node in self.__nodes.values():
paths[node.getKey()] = 2 ** 32
include_shortest_path[node.getKey()] = False
paths[start] = 0
for count in self.__nodes.values():
current = self.__minDistance(paths, include_shortest_path)
include_shortest_path[current.getKey()] = True
for node in self.__nodes.values():
if (
include_shortest_path[node.getKey()] == False and
self.__connected(current.getKey(), node.getKey()) and
paths[current.getKey()] != 2 ** 32 and
paths[current.getKey()] + self.__getWeightBetween(current.getKey(), node.getKey()) < paths[node.getKey()]
):
paths[node.getKey()] = paths[current.getKey()] + self.__getWeightBetween(current.getKey(), node.getKey())
print(paths)
return paths
As we can see here, two dictionaries are created. At the beginning, all nodes of the graph are captured. For each node, an entry is created in the paths table and set to 4.3 billion (infinity). At the same time an entry is created in the table include_shortest_path and marked as not used. After initialization, our start node in the paths table is assigned the value 0 as distance, since we are already at the node. Now we go through all nodes and determine for each node an account current, which should have the shortest distance. We then mark this as "used". Now we go through all nodes again and find the shortest path from our current node to all other nodes. This is where the auxiliary methods come into play. If a node exists, which is connected to our current node, and has no distance infinity, as well as its edge weight with the current weight of the current node, added is smaller than from the node itself, then we have found a short path, and update the path table. Each single pass of the outer For loop is one row in our example table. When everything is processed, we output the path list and return that as well.
Let's run the whole thing. The output looks like this:
DIJKSTRA SHORTEST PATH
{'E': 3.8, 'A': 0, 'B': 1.0, 'C': 5.8, 'F': 4.0, 'D': 1.4}
4.0
The first output is the path list which contains all distances. The second output is the distance between node A and node F.
I hope I was able to explain Dijkstra quite well 😄